ACID:
Action Consistency via Inverse Dynamics for Planning with World Models
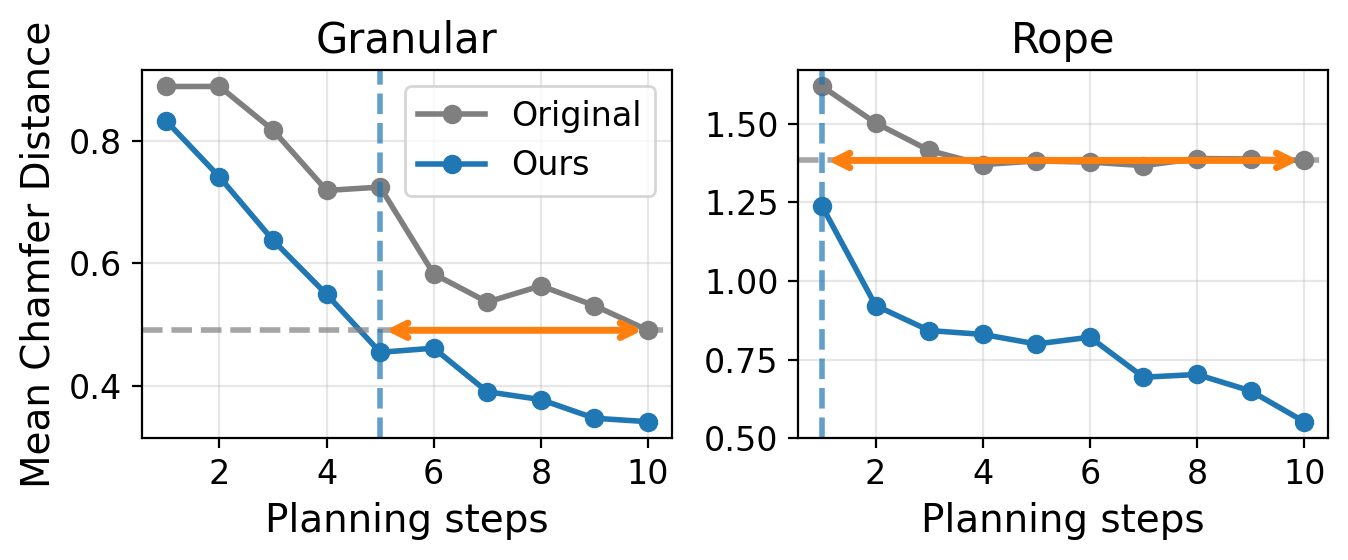
TL;DR: Decision-time planning scores a candidate only by how close its predicted final state is to the goal, never checking that the route there is realizable. ACID adds cycle action consistency: an inverse dynamics model infers the action behind each predicted transition, and its mismatch with the conditioning action becomes a per-step planning cost — improving planning across four world models and six tasks with substantially less compute.

Overall architecture of ACID. An MPC with CEM searches over candidate action sequences
a0:H-1 to minimize an augmented planning cost. The current observation
is encoded to z0, and the world model Fθ
unrolls a latent trajectory. An inverse dynamics model Gφ then
takes each predicted transition (žt, žt+1) and
infers the action that would explain it. The augmented cost combines a goal cost
(predicted final latent close to the goal) with an action consistency cost (the predicted
trajectory is realizable in the environment).
Abstract
Decision-time planning with action-conditioned world models has become a popular paradigm for embodied control. However, the standard planning cost judges a candidate solely by how close its predicted terminal state lies to the goal, leaving the realizability of the intermediate transitions unchecked — a predicted trajectory can look convincing while the environment rollout drifts away from it. In this paper, we propose ACID, a decision-time planning framework that introduces cycle action consistency: the action inferred backward from a predicted transition by an inverse dynamics model should recover the one that was conditioned on. We fold this per-step residual into the planning cost via a scale-invariant adaptive weight. Across four action-conditioned world models and six tasks spanning rigid and deformable manipulation, articulated control, and visual navigation, ACID consistently improves planning and matches the baseline's accuracy with substantially less planning compute.